Here’s the table of contents:
- 数据血缘图数据模型
- 算子引擎图数据模型
- 加载算子引擎和数据血缘全景图
- 分页加载算子列表
- 加载算子引擎全景图
- 加载数据血缘全景图
- 获取算子的API地址和样例入参
- 执行算子API并获取output输入给下一步等待执行的算子
- 存储指标ID【样例存储方式】【使用JSON串存储多个指标ID】
- 通过指标ID获取关联的数据血缘图谱
- 通过指标ID获取关联的指标算子图谱
- 数据血缘全景图相关的指标
- 算子引擎全景图相关的指标
- 将算子的指标ID列表整合到一个列表
数据血缘图数据模型
构建数据库->表->字段的血缘关系
Label
- 数据血缘
- MySQLDB(name,hupdatetime)
- MySQLDBTB(name,hupdatetime)
- MySQLDBTBField(name,hupdatetime)
Relationship
- 包含
- 关联
- 生成
- 导入
模拟数据
- 索引与约束
CREATE CONSTRAINT ON (n:MySQLDB) ASSERT n.name IS UNIQUE CREATE CONSTRAINT ON (n:MySQLDBTB) ASSERT n.name IS UNIQUE CREATE CONSTRAINT ON (n:MySQLDBTBField) ASSERT n.name IS UNIQUE - 数据库表与字段
merge (db:MySQLDB {name:'HackathonDB1'}) set db +={hupdatetime:'20200702121021'} merge (tb1:MySQLDBTB {name:'table1'}) set tb1 +={hupdatetime:'20200702121021'} merge (tb2:MySQLDBTB {name:'table2'}) set tb2 +={hupdatetime:'20200702121021'} merge (tb3:MySQLDBTB {name:'table3'}) set tb3 +={hupdatetime:'20200702121021'} merge (field1:MySQLDBTBField {name:'field1'}) set field1 +={hupdatetime:'20200702121021'} merge (field2:MySQLDBTBField {name:'field2'}) set field2 +={hupdatetime:'20200702121021'} merge (field3:MySQLDBTBField {name:'field3'}) set field3 +={hupdatetime:'20200702121021'} merge (field4:MySQLDBTBField {name:'field4'}) set field4 +={hupdatetime:'20200702121021'} merge (db)-[:包含]->(tb1) merge (db)-[:包含]->(tb2) merge (db)-[:包含]->(tb3) merge (tb1)-[:包含]->(field1) merge (tb1)-[:包含]->(field2) merge (tb2)-[:包含]->(field3) merge (tb3)-[:包含]->(field4) - 数据库表与字段
merge (db:MySQLDB {name:'HackathonDB2'}) set db +={hupdatetime:'20200702121021'} merge (tb1:MySQLDBTB {name:'dev_table1'}) set tb1 +={hupdatetime:'20200702121021'} merge (tb2:MySQLDBTB {name:'dev_table2'}) set tb2 +={hupdatetime:'20200702121021'} merge (tb3:MySQLDBTB {name:'dev_table3'}) set tb3 +={hupdatetime:'20200702121021'} merge (field1:MySQLDBTBField {name:'dev_field1'}) set field1 +={hupdatetime:'20200702121021'} merge (field2:MySQLDBTBField {name:'dev_field2'}) set field2 +={hupdatetime:'20200702121021'} merge (field3:MySQLDBTBField {name:'dev_field3'}) set field3 +={hupdatetime:'20200702121021'} merge (field4:MySQLDBTBField {name:'dev_field4'}) set field4 +={hupdatetime:'20200702121021'} merge (db)-[:包含]->(tb1) merge (db)-[:包含]->(tb2) merge (db)-[:包含]->(tb3) merge (tb1)-[:包含]->(field1) merge (tb1)-[:包含]->(field2) merge (tb2)-[:包含]->(field3) merge (tb3)-[:包含]->(field4) - 增加数据血缘标签
MATCH p=(n:MySQLDB)-[*..6]-() WITH NODES(p) AS nodeList UNWIND nodeList AS node MATCH (node) SET node:数据血缘
算子引擎图数据模型
构建算子模型之间的计算引擎模型
Label
- 算子(interface,name,hupdatetime,calculation_engine:{api:,input:,})
- 数据源
Relationship
- 输入(hupdatetime,operator_combine_list:[[算子1,算子2,算子3],[算子1,算子4,算子5]])
模拟数据
- 索引与约束
CREATE CONSTRAINT ON (n:算子) ASSERT n.interface IS UNIQUE - 算子
merge (c1:算子 {interface:'/read/d/transaction/c1'}) set c1 +={name:'c1',hupdatetime:'20200702121021',calculation_engine:'{api:\'http://localhost:7424/ongdb/read/d/transaction/c1\',input:\'?\'}'} merge (c2:算子 {interface:'/read/d/transaction/c1'}) set c2 +={name:'c2',hupdatetime:'20200702121021',calculation_engine:'{api:\'http://localhost:7424/ongdb/read/d/transaction/c2\',input:\'?\'}'} merge (c3:算子 {interface:'/read/d/transaction/c3'}) set c3 +={name:'c3',hupdatetime:'20200702121021',calculation_engine:'{api:\'http://localhost:7424/ongdb/read/d/transaction/c3\',input:\'?\'}'} merge (c4:算子 {interface:'/read/d/transaction/c4'}) set c4 +={name:'c4',hupdatetime:'20200702121021',calculation_engine:'{api:\'http://localhost:7424/ongdb/read/d/transaction/c4\',input:\'?\'}'} merge (c5:算子 {interface:'/read/d/transaction/c5'}) set c5 +={name:'c5',hupdatetime:'20200702121021',calculation_engine:'{api:\'http://localhost:7424/ongdb/read/d/transaction/c5\',input:\'?\'}'} merge (c6:算子 {interface:'/read/d/transaction/c6'}) set c6 +={name:'c6',hupdatetime:'20200702121021',calculation_engine:'{api:\'http://localhost:7424/ongdb/read/d/transaction/c6\',input:\'?\'}'} merge (c1)-[r1:输入]->(c3) set r1 +={hupdatetime:'20200702121021',operator_combine_list:'[[\'/read/d/transaction/c1\']]'} merge (c2)-[r2:输入]->(c3) set r2 +={hupdatetime:'20200702121021',operator_combine_list:'[[\'/read/d/transaction/c2\']]'} merge (c3)-[r3:输入]->(c5) set r3 +={hupdatetime:'20200702121021',operator_combine_list:'[[\'/read/d/transaction/c3\',\'/read/d/transaction/c4\']]'} merge (c4)-[r4:输入]->(c5) set r4 +={hupdatetime:'20200702121021',operator_combine_list:'[[\'/read/d/transaction/c3\',\'/read/d/transaction/c4\']]'} merge (c5)-[r5:输入]->(c6) set r5 +={hupdatetime:'20200702121021',operator_combine_list:'[[\'/read/d/transaction/c5\']]'} - 算子关联上表字段
match (c1:算子 {interface:'/read/d/transaction/c1'}) match (c2:算子 {interface:'/read/d/transaction/c1'}) match (c3:算子 {interface:'/read/d/transaction/c3'}) match (c4:算子 {interface:'/read/d/transaction/c4'}) match (c5:算子 {interface:'/read/d/transaction/c5'}) match (c6:算子 {interface:'/read/d/transaction/c6'}) match (field1:MySQLDBTBField {name:'field1'}) match (field2:MySQLDBTBField {name:'field2'}) match (field3:MySQLDBTBField {name:'field3'}) match (field4:MySQLDBTBField {name:'field4'}) match (dev_field1:MySQLDBTBField {name:'dev_field1'}) match (dev_field2:MySQLDBTBField {name:'dev_field2'}) match (dev_field3:MySQLDBTBField {name:'dev_field3'}) match (dev_field4:MySQLDBTBField {name:'dev_field4'}) merge (c1)<-[:数据源]-(field1) merge (c2)<-[:数据源]-(field2) merge (c2)<-[:数据源]-(dev_field1) merge (c2)<-[:数据源]-(dev_field2) merge (c3)<-[:数据源]-(field3) merge (c3)<-[:数据源]-(dev_field3) merge (c4)<-[:数据源]-(field4) merge (c5)<-[:数据源]-(dev_field4) - 增加算子引擎标签
MATCH p=(n:算子)-[*..6]-() WITH NODES(p) AS nodeList UNWIND nodeList AS node MATCH (node) SET node:算子引擎
加载算子引擎和数据血缘全景图
MATCH (n:算子引擎) OPTIONAL MATCH p=(n)-[]->() RETURN p
UNION ALL
MATCH (n:数据血缘) OPTIONAL MATCH p=(n)-[]->() RETURN p
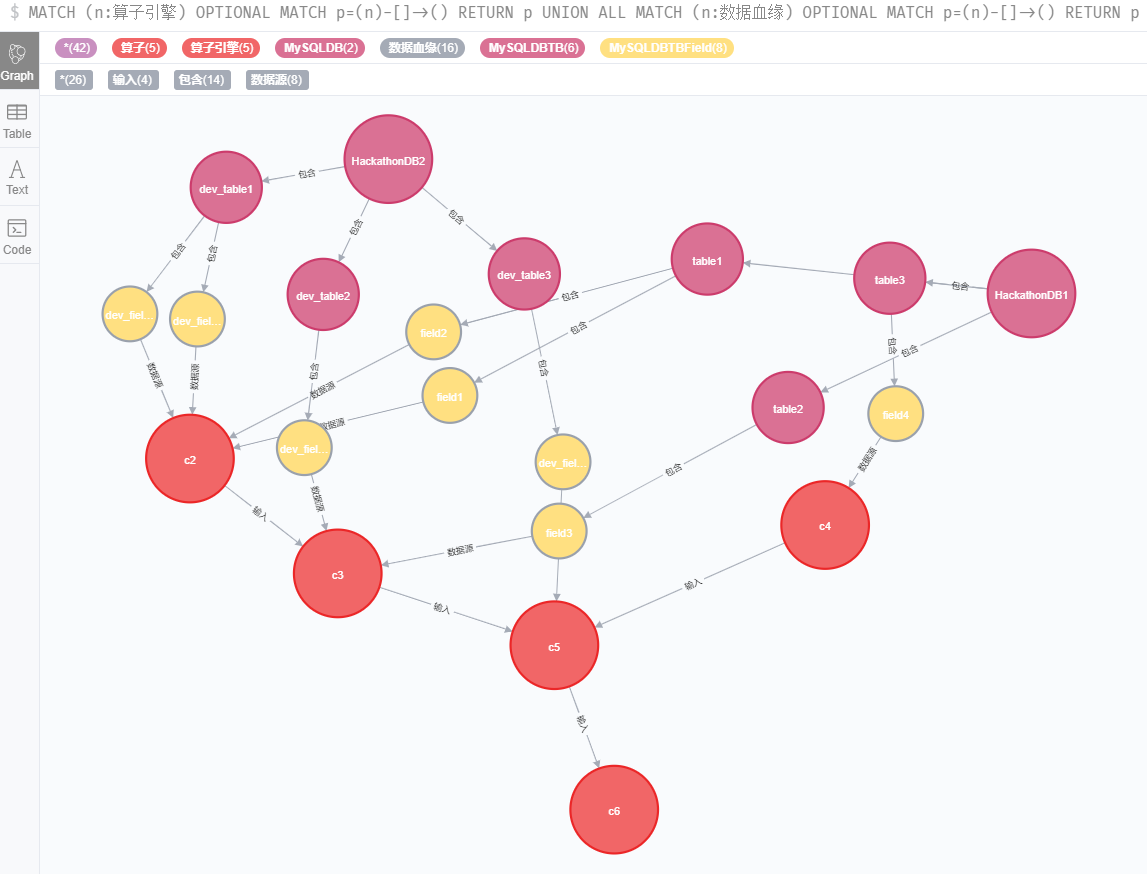
分页加载算子列表
MATCH (n:算子) RETURN n SKIP 0 LIMIT 10
加载算子引擎全景图
MATCH (n:算子引擎) OPTIONAL MATCH p=(n)-[]->(:算子引擎) RETURN p
加载数据血缘全景图
MATCH (n:数据血缘) OPTIONAL MATCH p=(n)-[]->(:数据血缘) RETURN p
获取算子的API地址和样例入参
MATCH (n:算子) WITH apoc.convert.fromJsonMap(n.calculation_engine) AS calculation_engine RETURN calculation_engine.api AS api,calculation_engine.input AS input
执行算子API并获取output输入给下一步等待执行的算子
- 创建两个测试算子
merge (c1:算子 {interface:'test1-/ongdb/read/d/transaction/commit'}) set c1 +={name:'test1算子',hupdatetime:'20200702121021',calculation_engine:'{api:\'http://localhost:7424/ongdb/read/d/transaction/commit\',input:\'{"statements": [{"statement": "match (n:算子) return n limit 10;"}],"user": "ongdb","password": "ongdb%dev"}\'}'} merge (c2:算子 {interface:'test2-/ongdb/read/d/transaction/commit'}) set c2 +={name:'test2算子',hupdatetime:'20200702121021',calculation_engine:'{api:\'http://localhost:7424/ongdb/read/d/transaction/commit\',input:\'{"statements": [{"statement": "match (n:算子) return n limit 10;"}],"user": "ongdb","password": "ongdb%dev"}\'}'} merge (c1)-[r1:输入]->(c2) set r1 +={hupdatetime:'20200702121021',operator_combine_list:'[[\'test1-/ongdb/read/d/transaction/commit\']]'} match (n:算子) where n.name IN ['test1算子','test2算子'] return n - 获取‘test1算子’的output之后解析出节点ID,输入到下一步算子继续执行【在第二步算子中拼接一个多节点匹配的查询然后执行】,并返回最终算子的执行结果
MATCH (n:算子) WHERE ID(n)=37675072 WITH apoc.convert.fromJsonMap(n.calculation_engine) AS calculation_engine,n WITH calculation_engine.api AS api,calculation_engine.input AS input,n WITH olab.http.post(api,input) AS resultString,n WITH apoc.convert.fromJsonMap(resultString).result.results[0].data[0].graph.nodes AS nodeList,n UNWIND nodeList AS node WITH COLLECT(node.id) AS ids,n MATCH (n)-[:输入]->(m) WITH apoc.convert.fromJsonMap(m.calculation_engine).input AS cypher,ids WITH apoc.convert.fromJsonMap(cypher).statements[0].statement AS cypher,ids WITH REPLACE(cypher,'return n limit 10;','WHERE ID(n) IN '+toString(apoc.convert.toJson(ids))+' return n') AS cypher CALL apoc.cypher.run(cypher,null) yield value return value - 多个算子按照入参的顺序执行
【需要拆分成多步】
【按1步传导执行】
【传入参之前判断‘输入’关系中operator参数数量 || 或者将一个完整的算子计算流程在数据层完全隔离,即不需要判断operator组合情况】
【多个入参需要先执行入参拿到output再执行下一步】
MATCH (n:算子) WHERE ID(n)=37674500 MATCH (n)-[r:输入]->(m) WITH SIZE(apoc.convert.fromJsonList(r.operator_combine_list))>1 RETURN m ...存储指标ID【样例存储方式】【使用JSON串存储多个指标ID】
MATCH (n:MySQLDBTBField) SET n.indicator_ids='["HIDSC1","HIDSC2"]' MATCH (n:算子) SET n.indicator_ids='["HIDSC1","HIDSC2"]'通过指标ID获取关联的数据血缘图谱
MATCH (n:MySQLDBTBField) WHERE ANY(indicator IN apoc.convert.fromJsonList(n.indicator_ids) WHERE indicator.code='HIND00000000008') CALL apoc.path.expand(n,NULL,'数据血缘',0,3) YIELD path RETURN path通过指标ID获取关联的指标算子图谱
MATCH (n:算子) WHERE ANY(indicator IN apoc.convert.fromJsonList(n.indicator_ids) WHERE indicator.code='HIND00000000012') MATCH p=(n)<-[*..6]-(:算子) RETURN p
数据血缘全景图相关的指标
1、数据库数量统计【MATCH (n:MySQLDB) RETURN COUNT(n) AS count】
2、数据表数量统计【MATCH (n:MySQLDBTB) RETURN COUNT(n) AS count】
3、数据字段数量统计【MATCH (n:MySQLDBTBField) RETURN COUNT(n) AS count】
4、被其它表使用最多的表前三个【MATCH (n:MySQLDBTBField) WHERE SIZE((n)<--(:MySQLDBTBField))=0 WITH n MATCH (n)<-[:包含]-(m:MySQLDBTB) WITH m MATCH p=(m)-[:包含]->(k:MySQLDBTBField)-->(f:MySQLDBTBField) RETURN m,COUNT(p) AS count ORDER BY count DESC LIMIT 3】
5、衍生字段数量【MATCH (n:MySQLDBTBField) WHERE SIZE((n)<--(:MySQLDBTBField))>1 RETURN COUNT(n)】
6、原始字段数量【MATCH (n:MySQLDBTBField) WHERE SIZE((n)<--(:MySQLDBTBField))=0 RETURN COUNT(n】
7、衍生表数量【MATCH (n:MySQLDBTBField) WHERE SIZE((n)<--(:MySQLDBTBField))>1 WITH n MATCH (n)<-[:包含]-(m:MySQLDBTB) RETURN COUNT(m)】
8、原始表数量【MATCH (n:MySQLDBTBField) WHERE SIZE((n)<--(:MySQLDBTBField))=0 WITH n MATCH (n)<-[:包含]-(m:MySQLDBTB) RETURN COUNT(m)】
算子引擎全景图相关的指标
1、获取数据的算子【MATCH (n:算子) WHERE n.is_get_data=true RETURN COUNT(n)】
2、计算算子【MATCH (n:算子) WHERE n.is_get_data=false RETURN COUNT(n)】
3、指标类型相关的算子统计【给SQL】
4、依赖算子最多的节点前三个【MATCH (n:算子)-[r]->(m:算子) RETURN m,SIZE(apoc.convert.fromJsonList(r.operator_combine_list)) AS size ORDER BY size DESC LIMIT 3】
5、被算子API使用的字段【MATCH (n:算子)<-[:获取数据]-(m:MySQLDBTBField) WHERE n.is_get_data=true RETURN COUNT(m)】
将算子的指标ID列表整合到一个列表
MATCH (n:`算子`) WITH apoc.convert.fromJsonList(n.indicator_ids) AS indicatorList
WHERE ANY(indicator IN indicatorList WHERE indicator.code<>'null') WITH indicatorList
UNWIND indicatorList AS indicator
RETURN COLLECT(indicator) AS indicatorList