Here’s the table of contents:
- 一、Jaccard相似度 - algo.similarity.jaccard - Mode.WRITE
- 二、余弦相似度 - algo.similarity.cosine - Mode.WRITE
- 三、Pearson相似度 - algo.similarity.pearson - Mode.WRITE
- 四、欧式距离 - algo.similarity.euclidean - Mode.WRITE
- 五、重叠相似度 - algo.similarity.overlap - Mode.WRITE
- 组织机构相似度计算
- 一、数据模型
- 二、创建测试数据
- 三、计算组织机构相似性
- 四、计算组织机构相似性并生成相似关系
- 备注
组织机构实体消歧实现方案可借鉴这个思路实现【后续会继续记录一个组织机构消歧实现方案】
一、Jaccard相似度 - algo.similarity.jaccard - Mode.WRITE
1、创建测试数据
CREATE (a:Person {name:'Alice'})
CREATE (b:Person {name:'Bob'})
CREATE (c:Person {name:'Charlie'})
CREATE (d:Person {name:'Dana'})
CREATE (i1:Item {name:'p1'})
CREATE (i2:Item {name:'p2'})
CREATE (i3:Item {name:'p3'})
CREATE (a)-[:LIKES]->(i1),
(a)-[:LIKES]->(i2),
(a)-[:LIKES]->(i3),
(b)-[:LIKES]->(i1),
(b)-[:LIKES]->(i2),
(c)-[:LIKES]->(i3)
2、运行相似度计算
不支持并发计算支持写入
MATCH (p:Person)-[:LIKES]->(i:Item)
WITH {item:id(p), categories: collect(distinct id(i))} as userData
WITH collect(userData) as data
CALL algo.similarity.jaccard(data, {write:true,showComputations:true,similarityCutoff:0.1}) yield p25, p50, p75, p90, p95, p99, p999, p100, nodes, similarityPairs, computations RETURN *
3、相似度计算结果
生成了一条SIMILAR关系线,更新了score属性;很明确可以看到人物节点之间的相似性得分。

4、algo.similarity.jaccard.stream - Mode.READ
并发计算,不支持写入
MATCH (p:Person)-[:LIKES]->(i:Item)
WITH {item:id(p), categories: collect(distinct id(i))} as userData
WITH collect(userData) as data
call algo.similarity.jaccard.stream(data,{topK:4,concurrency:4,similarityCutoff:-0.1}) yield item1, item2, count1, count2, intersection, similarity RETURN * ORDER BY item1,item2

二、余弦相似度 - algo.similarity.cosine - Mode.WRITE
1、创建测试数据
CREATE (a:Person {name:'Alice'})
CREATE (b:Person {name:'Bob'})
CREATE (c:Person {name:'Charlie'})
CREATE (d:Person {name:'Dana'})
CREATE (i1:Item {name:'p1'})
CREATE (i2:Item {name:'p2'})
CREATE (i3:Item {name:'p3'})
CREATE (a)-[:LIKES {stars:1}]->(i1),
(a)-[:LIKES {stars:2}]->(i2),
(a)-[:LIKES {stars:5}]->(i3),
(b)-[:LIKES {stars:1}]->(i1),
(b)-[:LIKES {stars:3}]->(i2),
(c)-[:LIKES {stars:4}]->(i3)
2、运行相似度计算
MATCH (i:Item) WITH i ORDER BY id(i) MATCH (p:Person) OPTIONAL MATCH (p)-[r:LIKES]->(i)
WITH {item:id(p), weights: collect(coalesce(r.stars,0))} as userData
WITH collect(userData) as data
CALL algo.similarity.cosine(data, {write:true,showComputations:true,similarityCutoff:0.1}) yield p25, p50, p75, p90, p95, p99, p999, p100, nodes, similarityPairs, computations RETURN *
3、algo.similarity.cosine.stream - Mode.READ
CALL algo.similarity.cosine.stream([{item:id, weights:[weights]}], {similarityCutoff:-1,degreeCutoff:0})
YIELD item1, item2, count1, count2, intersection, similarity - computes cosine distance
三、Pearson相似度 - algo.similarity.pearson - Mode.WRITE
1、创建测试数据
CREATE (a:Person {name:'Alice'})
CREATE (b:Person {name:'Bob'})
CREATE (c:Person {name:'Charlie'})
CREATE (d:Person {name:'Dana'})
CREATE (i1:Item {name:'p1'})
CREATE (i2:Item {name:'p2'})
CREATE (i3:Item {name:'p3'})
CREATE (i4:Item {name:'p4'})
CREATE (a)-[:LIKES {stars:1}]->(i1),
(a)-[:LIKES {stars:2}]->(i2),
(a)-[:LIKES {stars:3}]->(i3),
(a)-[:LIKES {stars:4}]->(i4),
(b)-[:LIKES {stars:2}]->(i1),
(b)-[:LIKES {stars:3}]->(i2),
(b)-[:LIKES {stars:4}]->(i3),
(b)-[:LIKES {stars:5}]->(i4),
(c)-[:LIKES {stars:3}]->(i1),
(c)-[:LIKES {stars:4}]->(i2),
(c)-[:LIKES {stars:4}]->(i3),
(c)-[:LIKES {stars:5}]->(i4),
(d)-[:LIKES {stars:3}]->(i2),
(d)-[:LIKES {stars:2}]->(i3),
(d)-[:LIKES {stars:5}]->(i4)
2、运行相似度计算
MATCH (i:Item) WITH i ORDER BY id(i) MATCH (p:Person) OPTIONAL MATCH (p)-[r:LIKES]->(i)
WITH {item:id(p), weights: collect(coalesce(r.stars,0))} as userData
WITH collect(userData) as data
CALL algo.similarity.pearson(data,{similarityCutoff:-0.1}) yield p25, p50, p75, p90, p95, p99, p999, p100, nodes, similarityPairs, computations RETURN *
3、algo.similarity.jaccard.stream - Mode.READ
MATCH (i:Item) WITH i ORDER BY i MATCH (p:Person) OPTIONAL MATCH (p)-[r:LIKES]->(i)
WITH p, i, r ORDER BY id(p), id(i) WITH {item:id(p), weights: collect(coalesce(r.stars,$missingValue))} as userData
WITH collect(userData) as data
call algo.similarity.pearson.stream(data,{similarityCutoff:-0.1}) yield item1, item2, count1, count2, intersection, similarity RETURN item1, item2, count1, count2, intersection, similarity ORDER BY item1,item2
四、欧式距离 - algo.similarity.euclidean - Mode.WRITE
1、创建测试数据
CREATE (a:Person {name:'Alice'})
CREATE (b:Person {name:'Bob'})
CREATE (c:Person {name:'Charlie'})
CREATE (d:Person {name:'Dana'})
CREATE (i1:Item {name:'p1'})
CREATE (i2:Item {name:'p2'})
CREATE (i3:Item {name:'p3'})
CREATE (a)-[:LIKES {stars:1}]->(i1),
(a)-[:LIKES {stars:2}]->(i2),
(a)-[:LIKES {stars:5}]->(i3),
(b)-[:LIKES {stars:1}]->(i1),
(b)-[:LIKES {stars:3}]->(i2),
(c)-[:LIKES {stars:4}]->(i3)
2、运行相似度计算
MATCH (i:Item) WITH i ORDER BY id(i) MATCH (p:Person) OPTIONAL MATCH (p)-[r:LIKES]->(i)
WITH {item:id(p), weights: collect(coalesce(r.stars,0))} AS userData
WITH collect(userData) AS data
CALL algo.similarity.euclidean(data, {similarityCutoff:-0.1}) YIELD p25, p50, p75, p90, p95, p99, p999, p100, nodes, similarityPairs, computations RETURN *
3、algo.similarity.jaccard.stream - Mode.READ
MATCH (i:Item) WITH i ORDER BY id(i) MATCH (p:Person) OPTIONAL MATCH (p)-[r:LIKES]->(i)
WITH {item:id(p), weights: collect(coalesce(r.stars,$missingValue))} AS userData
WITH collect(userData) AS data
CALL algo.similarity.euclidean.stream(data,{similarityCutoff:-0.1}) YIELD item1, item2, count1, count2, intersection, similarity RETURN item1, item2, count1, count2, intersection, similarity ORDER BY item1,item2
五、重叠相似度 - algo.similarity.overlap - Mode.WRITE
1、创建测试数据
CREATE (a:Person {name:'Alice'})
CREATE (b:Person {name:'Bob'})
CREATE (c:Person {name:'Charlie'})
CREATE (d:Person {name:'Dana'})
CREATE (i1:Item {name:'p1'})
CREATE (i2:Item {name:'p2'})
CREATE (i3:Item {name:'p3'})
CREATE (a)-[:LIKES]->(i1),
(a)-[:LIKES]->(i2),
(a)-[:LIKES]->(i3),
(b)-[:LIKES]->(i1),
(b)-[:LIKES]->(i2),
(c)-[:LIKES]->(i3)
2、运行相似度计算
MATCH (p:Person)-[:LIKES]->(i:Item)
WITH {item:id(p), categories: collect(distinct id(i))} as userData
WITH collect(userData) as data
CALL algo.similarity.overlap(data, {similarityCutoff:-0.1}) yield p25, p50, p75, p90, p95, p99, p999, p100, nodes, similarityPairs, computations RETURN p25, p50, p75, p90, p95, p99, p999, p100, nodes, similarityPairs, computations
3、algo.similarity.jaccard.stream - Mode.READ
MATCH (p:Person)-[:LIKES]->(i:Item)
WITH {item:id(p), categories: collect(distinct id(i))} as userData
WITH collect(userData) as data
call algo.similarity.overlap.stream(data,{similarityCutoff:-0.1}) yield item1, item2, count1, count2, intersection, similarity RETURN item1, item2, count1, count2, intersection, similarity ORDER BY item1,item2
组织机构相似度计算
一、数据模型
1、LABEL
- LABEL:组织机构簇心
- LABEL:组织机构
- LABEL:中文名称/中文简称/中文拼音简称/英文名称/英文简称/成立日期/法人代表/总经理/其它负责人/联系人/电子邮箱/注册地址/办公地址/联系地址/注册所在城市/联系所在城市/注册所在区县/网址/联系电话/注册地址邮编/联系地址邮编/传真/统一社会信用代码/交易代码/所属行业/注册资本
2、RELATIONSHIP
- 关联别名【中文名称/中文简称/中文拼音简称/英文名称/英文简称】
- 关联日期【成立日期】
- 关联人【法人代表/总经理/其它负责人/联系人】
- 关联邮箱【电子邮箱】
- 关联地址【注册地址/办公地址/联系地址】
- 关联城市【注册所在城市/联系所在城市】
- 关联区县【注册所在区县】
- 关联网址【网址】
- 关联电话【联系电话】
- 关联邮编【注册地址邮编/联系地址邮编】
- 关联传真【传真】
- 关联信用代码【统一社会信用代码】
- 关联交易代码【交易代码】
- 关联行业【所属行业】
- 关联资本【注册资本(元)】
弃用数据:货币单位/企业属性/简介/主营业务等纯文本数据与特有性不强的数据
二、创建测试数据
- 嘉实基金
MERGE (n0:组织机构 {name:'嘉实基金'}) SET n0:中文名称 MERGE (n1:组织机构 {name:'嘉实JS'}) SET n1:中文简称 MERGE (n2:组织机构 {name:'JIA SHI JI JIN'}) SET n2:中文拼音简称 MERGE (n3:组织机构 {name:'HARVEST FUND'}) SET n3:英文名称 MERGE (n4:组织机构 {name:'HARVEST Inc.'}) SET n4:英文简称 MERGE (n5:成立日期 {name:'20180101'}) MERGE (n6:人物 {name:'赵总'}) SET n6:法人代表 MERGE (n7:人物 {name:'李总'}) SET n7:总经理 MERGE (n8:电子邮箱 {name:'jsfund@jsfund.cn'}) MERGE (n9:城市 {name:'北京'}) MERGE (n10:区县 {name:'东城区'}) MERGE (n11:网址 {name:'www.jsfund.cn'}) MERGE (n12:联系电话 {name:'010-65215000'}) MERGE (n13:邮编 {name:'10000'}) SET n13:注册地址邮编 MERGE (n14:邮编 {name:'10001'}) SET n14:联系地址邮编 MERGE (n15:传真 {name:'5000'}) MERGE (n16:交易代码 {name:'10901'}) MERGE (n17:所属行业 {name:'金融业'}) MERGE (n18:注册资本 {name:'10000000'}) MERGE (n0)-[:关联别名]->(n1) MERGE (n0)-[:关联别名]->(n2) MERGE (n0)-[:关联别名]->(n3) MERGE (n0)-[:关联别名]->(n4) MERGE (n0)-[:关联别名]->(n4) MERGE (n0)-[:关联日期]->(n5) MERGE (n0)-[:关联人]->(n6) MERGE (n0)-[:关联人]->(n7) MERGE (n0)-[:关联邮箱]->(n8) MERGE (n0)-[:关联城市]->(n9) MERGE (n0)-[:关联城市]->(n9) MERGE (n0)-[:关联区县]->(n10) MERGE (n0)-[:关联网址]->(n11) MERGE (n0)-[:关联电话]->(n12) MERGE (n0)-[:关联邮编]->(n13) MERGE (n0)-[:关联邮编]->(n14) MERGE (n0)-[:关联传真]->(n15) MERGE (n0)-[:关联交易代码]->(n16) MERGE (n0)-[:关联行业]->(n17) MERGE (n0)-[:关联资本]->(n18) - 嘉实
MERGE (n0:组织机构 {name:'嘉实'}) SET n0:中文名称 MERGE (n1:组织机构 {name:'嘉fund'}) SET n1:中文简称 MERGE (n2:组织机构 {name:'JIA SHI'}) SET n2:中文拼音简称 MERGE (n3:组织机构 {name:'HARVEST FUND'}) SET n3:英文名称 MERGE (n4:组织机构 {name:'HARVEST Inc.'}) SET n4:英文简称 MERGE (n5:成立日期 {name:'20180102'}) MERGE (n6:人物 {name:'学军总'}) SET n6:法人代表 MERGE (n7:人物 {name:'丹总'}) SET n7:总经理 MERGE (n8:电子邮箱 {name:'jsfund@jsfund.cn'}) MERGE (n9:城市 {name:'北京'}) MERGE (n10:区县 {name:'东城区'}) MERGE (n11:网址 {name:'www.jsfund.cn'}) MERGE (n12:联系电话 {name:'010-65215000'}) MERGE (n13:邮编 {name:'10001'}) SET n13:注册地址邮编 MERGE (n14:邮编 {name:'10001'}) SET n14:联系地址邮编 MERGE (n15:传真 {name:'5000'}) MERGE (n16:交易代码 {name:'10901'}) MERGE (n17:所属行业 {name:'基金业'}) MERGE (n18:注册资本 {name:'10002000'}) MERGE (n0)-[:关联别名]->(n1) MERGE (n0)-[:关联别名]->(n2) MERGE (n0)-[:关联别名]->(n3) MERGE (n0)-[:关联别名]->(n4) MERGE (n0)-[:关联别名]->(n4) MERGE (n0)-[:关联日期]->(n5) MERGE (n0)-[:关联人]->(n6) MERGE (n0)-[:关联人]->(n7) MERGE (n0)-[:关联邮箱]->(n8) MERGE (n0)-[:关联城市]->(n9) MERGE (n0)-[:关联城市]->(n9) MERGE (n0)-[:关联区县]->(n10) MERGE (n0)-[:关联网址]->(n11) MERGE (n0)-[:关联电话]->(n12) MERGE (n0)-[:关联邮编]->(n13) MERGE (n0)-[:关联邮编]->(n14) MERGE (n0)-[:关联传真]->(n15) MERGE (n0)-[:关联交易代码]->(n16) MERGE (n0)-[:关联行业]->(n17) MERGE (n0)-[:关联资本]->(n18) - 嘉实远见
MERGE (n0:组织机构 {name:'嘉实远见'}) SET n0:中文名称 MERGE (n1:组织机构 {name:'远见'}) SET n1:中文简称 MERGE (n2:组织机构 {name:'JIA SHI YUAN JIAN'}) SET n2:中文拼音简称 MERGE (n3:组织机构 {name:'HARVEST YJ'}) SET n3:英文名称 MERGE (n4:组织机构 {name:'HARVEST YJ Inc.'}) SET n4:英文简称 MERGE (n5:成立日期 {name:'20190102'}) MERGE (n6:人物 {name:'M总'}) SET n6:法人代表 MERGE (n7:人物 {name:'K总'}) SET n7:总经理 MERGE (n8:电子邮箱 {name:'jsfundyj@jsfund.cn'}) MERGE (n9:城市 {name:'北京'}) MERGE (n10:区县 {name:'东城区'}) MERGE (n11:网址 {name:'www.jsfundyj.cn'}) MERGE (n12:联系电话 {name:'010-65315002'}) MERGE (n13:邮编 {name:'10003'}) SET n13:注册地址邮编 MERGE (n14:邮编 {name:'10002'}) SET n14:联系地址邮编 MERGE (n15:传真 {name:'5001'}) MERGE (n16:交易代码 {name:'10501'}) MERGE (n17:所属行业 {name:'金融科技'}) MERGE (n18:注册资本 {name:'5002000'}) MERGE (n0)-[:关联别名]->(n1) MERGE (n0)-[:关联别名]->(n2) MERGE (n0)-[:关联别名]->(n3) MERGE (n0)-[:关联别名]->(n4) MERGE (n0)-[:关联别名]->(n4) MERGE (n0)-[:关联日期]->(n5) MERGE (n0)-[:关联人]->(n6) MERGE (n0)-[:关联人]->(n7) MERGE (n0)-[:关联邮箱]->(n8) MERGE (n0)-[:关联城市]->(n9) MERGE (n0)-[:关联城市]->(n9) MERGE (n0)-[:关联区县]->(n10) MERGE (n0)-[:关联网址]->(n11) MERGE (n0)-[:关联电话]->(n12) MERGE (n0)-[:关联邮编]->(n13) MERGE (n0)-[:关联邮编]->(n14) MERGE (n0)-[:关联传真]->(n15) MERGE (n0)-[:关联交易代码]->(n16) MERGE (n0)-[:关联行业]->(n17) MERGE (n0)-[:关联资本]->(n18)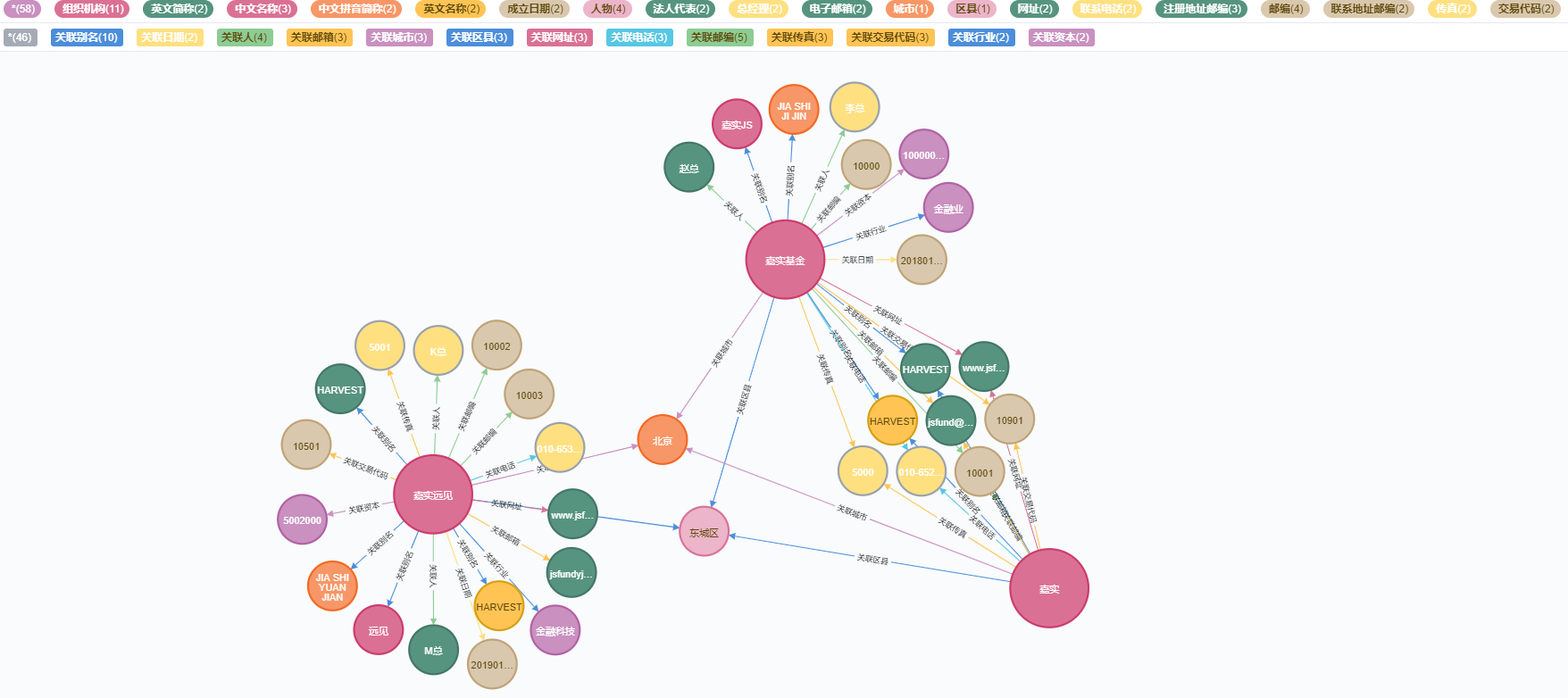
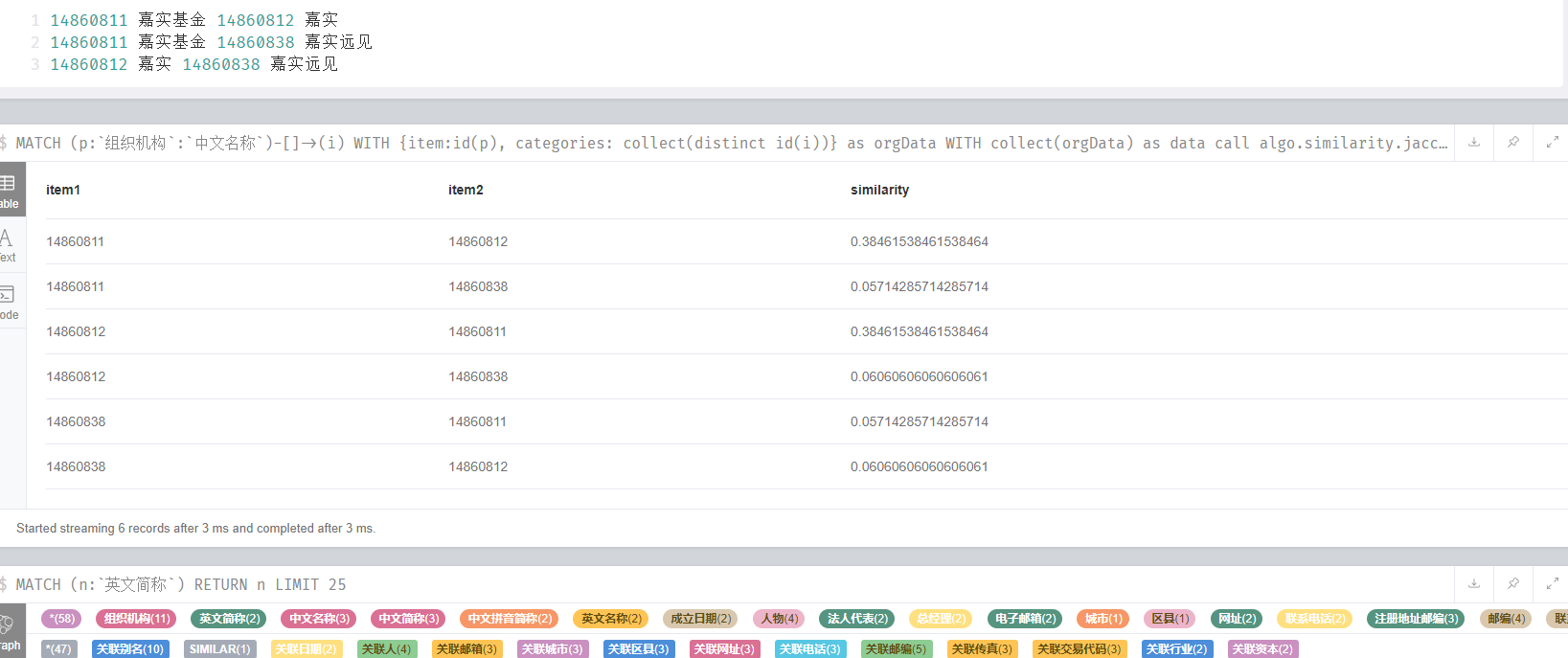
三、计算组织机构相似性
不支持并发计算支持写入
MATCH (p:`组织机构`:`中文名称`)-[]->(i)
WITH {item:id(p), categories: collect(distinct id(i))} as orgData
WITH collect(orgData) as data
CALL algo.similarity.jaccard(data, {write:false,showComputations:true,similarityCutoff:0.1}) yield p25, p50, p75, p90, p95, p99, p999, p100, nodes, similarityPairs, computations RETURN *
四、计算组织机构相似性并生成相似关系
并发计算,不支持写入
MATCH (p:`组织机构`:`中文名称`)-[]->(i)
WITH {item:id(p), categories: collect(distinct id(i))} as orgData
WITH collect(orgData) as data
call algo.similarity.jaccard.stream(data,{topK:4,concurrency:4,similarityCutoff:-0.1}) yield item1, item2, count1, count2, intersection, similarity RETURN * ORDER BY item1,item2
- 14860811 嘉实基金 14860812 嘉实
- 14860811 嘉实基金 14860838 嘉实远见
- 14860812 嘉实 14860838 嘉实远见
备注
neo4j-graph-algorithms包相似度计算源码位置: algo/src/main/java/org/neo4j/graphalgo/similarity
PREVIOUSONgDB图数据库集群数据导入测试案例
NEXTONgDB三节点部署说明